
If I ask you, “What is AI?” There are improbable chances of answering this straightforward question incorrectly. Everyone, even those from generation X or the millennial, has a fundamental idea of what artificial intelligence is and where it is taking our world today. But I doubt that those who are familiar with AI are also familiar with some of its algorithms. While not mandatory for everyone, it is always preferable to be knowledgeable in advance.
Therefore, the purpose of this blog is to advance your understanding of AI by introducing you to the many categories of AI algorithms you need to be familiar with. You will receive a concise explanation along with examples in an approachable tone. Keep reading till the very end.
What is AI?
AI is a scientific and engineering endeavor to make intelligent systems, particularly intelligent computer programs. It is related to the job of utilizing computers to comprehend human intelligence. In simple words, artificial intelligence uses computers and other devices to simulate how the human mind solves problems and makes decisions.
Types of Artificial Intelligence Algorithms
Artificial Intelligence algorithms can be divided into various types based on their functionalities, the types of data they use, and the result that is expected.
Broady AI algorithms can be categorized into four types:
- Supervised learning
- Unsupervised Learning
- Semi-supervised Learning
- Reinforcement Learning
1. Supervised learning
In supervised learning, the output of algorithms is predicted based on well-labeled training data. Labeled data is a word used to describe input data that has already been given the proper output. In supervised learning, the algorithm’s training data serve as the supervisor, instructing the system on how to accurately forecast the output.
Some examples of algorithms based on supervised learning are –
-
Artificial Neural networks

Source: serious-science.org
Artificial Neural Networks (ANN) are brain-inspired algorithms that are used to foresee problems and model complex patterns. These networks can be used to create the next generation of computers because they are already being used for complicated analysis in a variety of disciplines, from engineering to medicine. Due to the fact that ANN learns from sample data sets, they are utilized for a variety of applications, including image recognition, speech recognition, machine translation, and medical diagnosis.
-
Naive Bayes
Naive Bayes algorithms are based on the Bayes Theorem. Being a probabilistic classifier, it makes predictions based on the likelihood that an object will occur. It is a family of algorithms rather than a single algorithm, and they are all based on the idea that every pair of features being classified is independent of the other. It is mostly employed in text categorization with a large training set. The Naive Bayes Classifier is one of the most straightforward and efficient classification algorithms available today. It aids in the development of quick machine-learning models capable of making accurate predictions. Spam filtration, Sentimental analysis, and article classification are a few examples of Naive Bayes algorithms.
-
Linear and Logistic Regression
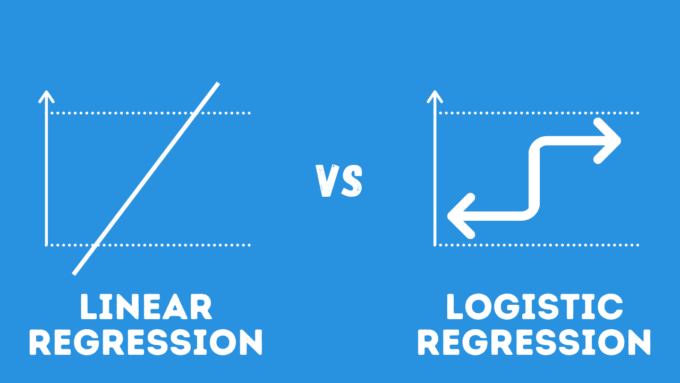
Source: ai-pool.com
The two well-known AI algorithms are linear regression and logistic regression. Both algorithms create predictions using a labeled dataset. But their primary distinction is in how they are employed. While Logistic Regression is used to solve Classification difficulties, Linear Regression is used to solve Regression problems. In the event that the independent variables change, linear regression is employed to estimate the dependent variable. For instance, estimate the cost of a house. Contrarily, logistic regression is used to determine an event’s probability. Determine whether tissue is benign or cancerous, for instance.
-
SVM
Support Vector Machine (SVM) is used for both classification and regression. Finding a hyperplane in an N-dimensional space that clearly classifies the data points is the goal of the SVM method. Due to the use of support vectors, a subset of training points in the decision function, SVM is effective in high-dimensional scenarios and utilizes less memory. SVMs are utilized in web pages, intrusion detection, face identification, email categorization, gene classification, and handwriting recognition, among many other applications.
-
KNN
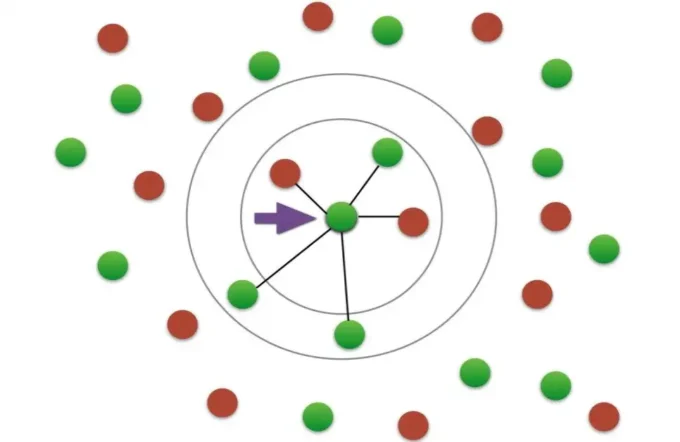
Source: unite.ai
A non-parametric supervised learning classifier called k-NN employs closeness to categorize or anticipate how a given data point will be grouped. Although it can be applied to classification or regression issues, it is commonly employed as a classification algorithm because it relies on the idea that comparable points can be discovered close to one another. Because it produces extremely accurate predictions, the KNN algorithm can compete with the most accurate models.
-
Random Forest
Random Forest, as the name implies, is a classifier that uses a number of decision trees on different subsets of the provided dataset and averages them to increase the dataset’s predictive accuracy. Instead of depending on a single decision tree, the random forest uses forecasts from each tree and predicts the result based on the votes of the majority of predictions. Numerous businesses, including finance, stock trading, medicine, and e-commerce, use random forests. It is utilized to forecast factors like patient history, customer behavior, and safety that are crucial to the smooth operation of these sectors.
2. Unsupervised Learning
Unsupervised learning is a technique in which algorithms are not supervised by training datasets, as the name implies. Instead, algorithms themselves go through the provided data to uncover hidden trends and insights. It is comparable to the learning process that occurs in the human brain while learning something new. Finding the underlying structure of a dataset, classifying the data into groups based on similarities, and representing the dataset in a compressed format.
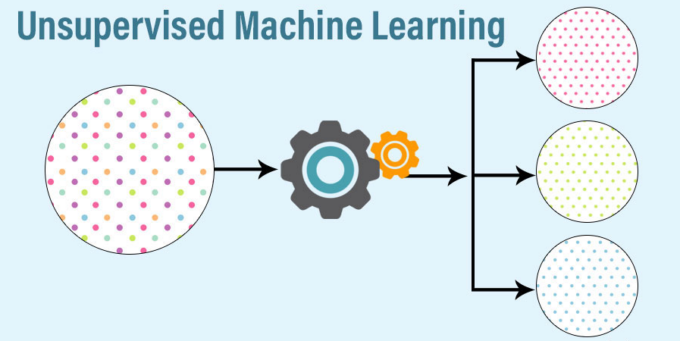
Source: unite.ai
-
K-means clustering
K-Means clustering divides objects into clusters that have things in common and are different from things in another cluster. It is an iterative approach that separates the unlabeled dataset into k distinct clusters, each of which contains just one dataset and shares a set of characteristics. The number of clusters you need to build must be specified in the system. Detecting insurance fraud, cyber-profiling criminals, and call record detail analysis are some of its application cases.
-
Hierarchical clustering
The process of clustering unlabeled datasets into groups is known as hierarchical clustering, commonly abbreviated as HCA. With this approach, we create a tree-like structure known as a dendrogram that represents the hierarchy of clusters. Charting Evolution with Phylogenetic Trees and monitoring Viruses through Phylogenetic Trees are two examples of the algorithm’s practical applications.
-
Principal Component Analysis (PCA)
A well-liked unsupervised learning method for lowering the dimensionality of data is principal component analysis. While minimizing information loss, it simultaneously improves interpretability. It makes data easier to plot in 2D and 3D and aids in identifying the dataset’s most important properties. Finding a series of linear combinations of variables is made easier by PCA.
3. Semi-supervised Learning
Source: finsliqblog.com
An AI technique known as semi-supervised learning sits in the middle of the supervised and unsupervised learning spectrum. During the training phase, it uses a combination of labeled and unlabeled datasets. A text document classifier is a typical example of a semi-supervised learning application. It would be nearly impossible to find a significant number of labeled text documents in this type of situation, making semi-supervised learning the best option.
4. Reinforcement Learning
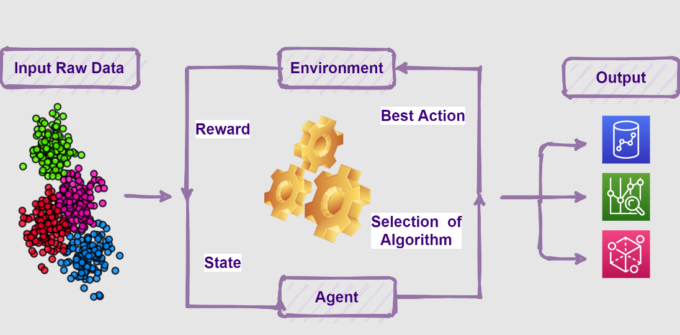
Source: inwinstack.com
Reinforcement learning involves acting appropriately to maximize reward in a certain circumstance. It is used by a variety of programs and machines to determine the optimal course of action to pursue in a given circumstance. There is no perfect solution in this situation, but the reinforcement agent chooses how to carry out the mandated mission. It is obligated to gain knowledge from its experience in the absence of a training dataset.
Reinforcement Learning Practical Applications include autonomous vehicles, cooling in data centers, control of traffic lights, healthcar, image manipulation, Robotics, NLP, and Marketing.
What’s Next?
Has anything in the above blog caught your attention? Any examples of how the algorithms have been used in real-world situations? If so, your next move might be to begin working on a project linked to it or you can also enroll in Board Infinity’s Machine Learning Engineer, an Artificial Intelligence course to learn from industry professionals.
Click here: Board Infinity for more information.





